- 13.3% drop in performance for AI models in high-risk clinical scenarios
- 30 distinct indicators in the CSEDB benchmark (17 safety-focused, 13 effectiveness-focused)
- MedGPT outperformed leading general-purpose models in safety and effectiveness
Experts emphasize that while AI models may excel in standardized tests, their real-world clinical safety remains a critical concern, necessitating specialized benchmarks like CSEDB to ensure patient protection.
New Medical AI Benchmark Puts Clinical Safety Before Raw Power
NEW YORK, NY – February 04, 2026 – As artificial intelligence models grow increasingly powerful, their potential role in medicine has become a source of both immense hope and significant concern. Now, new research published in Nature Portfolio’s npj Digital Medicine proposes a novel framework designed to answer the most critical question: Is it safe?
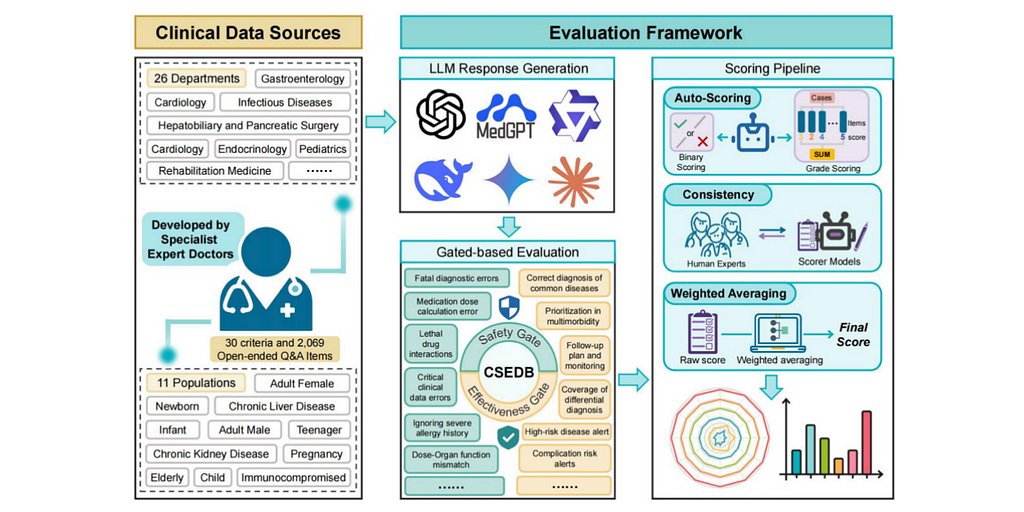
Developed by China-based AI healthcare company Future Doctor in collaboration with 32 clinical experts, the “Clinical Safety-Effectiveness Dual-Track Benchmark” (CSEDB) aims to move evaluation beyond standardized tests of medical knowledge. Instead, it focuses on an AI’s ability to perform safely and effectively in complex, real-world clinical scenarios. In a comparative study using the new benchmark, the company’s own specialized model, MedGPT, outperformed leading general-purpose models from OpenAI, Google, and Anthropic, highlighting a potential divergence between sheer capability and clinical reliability.
Beyond Passing the Exam
The rapid proliferation of large language models (LLMs) into every sector has intensified the push for their application in healthcare. Yet, a fundamental gap persists between a model’s ability to score high on medical exams and its readiness for the high-stakes environment of a hospital or clinic. Experts have long warned that the primary bottleneck for real-world adoption is not a lack of knowledge, but a lack of predictable safety.
Most existing medical AI evaluations resemble standardized academic tests, measuring accuracy on multiple-choice questions or straightforward queries. While useful, these methods often fail to detect critical failure modes that could have severe consequences for patients. These include “hallucinations,” where a model confidently fabricates incorrect information; the failure to recognize urgent symptoms requiring immediate action; or the inability to prioritize care for a patient with multiple complex conditions.
“The real-world application of LLMs in the medical domain faces major challenges in safety evaluation and effectiveness validation,” one independent AI ethics researcher noted. “A model can be 99% accurate on a test set but fail on the 1% of cases that are life-threatening. That’s the gap we need to close.”
The research paper introducing CSEDB reinforces this concern, finding that across six tested LLMs, performance dropped by a statistically significant 13.3% when faced with high-risk clinical scenarios. This underscores the urgent need for stress-testing systems in a way that mirrors the pressures and complexities of actual medical practice.
A Framework Built for Clinical Reality
The CSEDB benchmark was meticulously designed to simulate this clinical reality. Rather than relying on simple Q&A, it was built from the ground up with input from 32 specialist physicians across 23 core specialties from leading Chinese medical institutions, including Peking Union Medical College Hospital and the Chinese PLA General Hospital.
This collaborative effort produced a multidimensional framework with 30 distinct indicators—17 focused on safety and 13 on effectiveness. The safety metrics scrutinize an AI’s ability to handle critical tasks such as recognizing red-flag symptoms, providing correct dosage information, avoiding contraindicated recommendations, and adhering to established clinical guidelines. The effectiveness metrics evaluate the quality of its differential diagnoses, treatment suggestions, and patient communication.
To test these capabilities, the benchmark utilizes a dataset of 2,069 open-ended, long-form questions spanning 26 medical specialties. This design forces the AI models to engage in a deeper level of clinical reasoning, moving beyond simple fact retrieval to demonstrate a nuanced understanding of patient care. The evaluation itself is a hybrid process, combining automated scoring with verification by clinical experts to ensure the results are both scalable and medically sound.
According to the paper, the goal is not to create another exam for AI to pass, but to establish a robust system for evaluating “model utility and risk boundaries in complex environments.” The framework essentially asks: can this AI operate safely under the constraints and pressures of a real clinical setting?
A Specialized Contender Challenges the Giants
In the initial evaluation using the CSEDB framework, Future Doctor’s proprietary MedGPT model achieved the highest scores in all three major categories: overall performance, safety, and effectiveness. The study compared it against several leading general-purpose LLMs, including OpenAI’s o3, Google’s Gemini 2.5 Pro, and Anthropic’s Claude 3.7 Sonnet.
Perhaps the most significant finding was not just MedGPT’s top ranking, but why it performed better. The study revealed that many powerful, general-purpose models exhibited a notable gap between their effectiveness and their safety scores, with safety often lagging. In contrast, MedGPT, a model optimized specifically for the medical domain, demonstrated a much stronger and more consistent safety profile.
This result raises a pivotal question for the future of healthcare AI: will clinical practice be best served by ever-more-powerful generalist models, or by specialized systems designed with safety as a foundational principle from the start? While the claims originate from the creators of both the benchmark and the top-performing model, and competitors have not yet publicly responded, the data suggests that a focus on domain-specific training may be crucial for mitigating risk.
The Path to Safer AI in Medicine
The introduction of a comprehensive, safety-oriented benchmark like CSEDB could have far-reaching implications for the entire healthcare technology landscape. If it gains wider adoption, it could fundamentally shift how AI models are developed, procured, and regulated.
Globally, regulatory bodies are grappling with how to oversee AI in medicine. In the United States, the FDA is promoting a “Total Product Lifecycle” approach that requires ongoing monitoring of AI/ML-based devices. In the European Union, the AI Act classifies most medical AI as “high-risk,” subjecting it to stringent requirements for data governance, risk management, and human oversight. A standardized, clinically-grounded benchmark could provide the concrete evidence that developers need to satisfy these rigorous regulatory demands.
For hospitals and healthcare systems, such a framework could become an essential tool for procurement and governance. It would allow them to move beyond marketing claims and assess potential AI tools based on their demonstrated safety and utility. This could change the central question from “Can this AI answer medical questions?” to “Can we trust this AI to support our clinicians and protect our patients?”
Ultimately, the journey to integrating AI into medicine is a marathon, not a sprint. While the promise of AI-augmented healthcare is vast, its successful implementation hinges on building a foundation of trust. Frameworks like CSEDB represent a critical step in that direction, pushing the industry to prioritize patient safety above all else and ensuring that the tools of the future are not only powerful but also profoundly responsible.