AI's Reality Check: Top Models Fail Expert Judgment 30% of the Time
- 30% failure rate: Top AI models fail expert judgment 30% of the time
- 72.7% alignment: OpenAI’s GPT 5.5 leads with 72.7% expert alignment
- 20% low scores: Some models score as low as 20% in legal and health sectors
Experts agree that current AI models, despite high benchmark scores, fall short of reliable professional judgment, requiring significant improvements before safe deployment in critical fields.
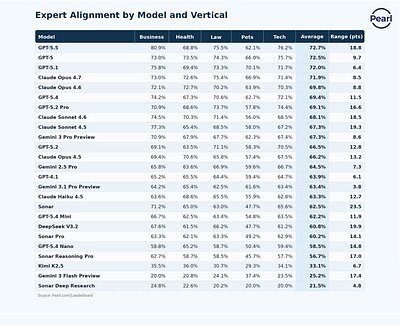
AI's Reality Check: Top Models Fail Expert Judgment 30% of the Time
SAN FRANCISCO, CA – May 13, 2026 – Leading artificial intelligence systems from top developers like OpenAI, Anthropic, and Google DeepMind are failing to meet the standards of licensed professionals nearly a third of the time, according to a sweeping new evaluation that challenges the narrative of AI’s rapid progress. The study, published by Pearl Enterprise, found that even the most advanced AI models align with expert judgment in only about 70% of cases, raising critical questions about their readiness for high-stakes deployment in fields like law, medicine, and finance.
The findings, released as the Pearl Expert Alignment Leaderboard, evaluated 25 of the world's frontier AI models against a battery of approximately 510 real-world professional questions. While OpenAI’s GPT 5.5 led the pack with 72.7% expert alignment, the results reveal a stark truth: the impressive scores seen on public benchmarks are not consistently translating into the reliable, nuanced judgment required for professional tasks. For many businesses betting on AI for critical functions, the report serves as a sobering reality check.
“Benchmarks measure whether a model can pass a test. We're asking whether a professional would trust the answer, and right now, the answer is no,” said Andy Kurtzig, CEO of Pearl, in the press release. “That's the gap companies need to solve before deploying AI in high-stakes environments. Almost right is still wrong.”
Beyond the Benchmarks
The report's central argument is that the AI industry may be optimizing for the wrong metrics. Public benchmarks such as GPQA and SWE-bench have become the standard for demonstrating model superiority, driving a competitive race to the top of leaderboards. However, Pearl's evaluation suggests these gains may be partially illusory, creating a phenomenon some researchers call 'benchmark gaming'—where models become exceptionally good at passing tests without developing the generalized, real-world intelligence those tests are meant to measure.
This disconnect is a growing concern within the AI ethics and safety community. While models can retrieve facts and mimic patterns with stunning accuracy, they often lack the deep contextual understanding and common-sense reasoning that underpins human expertise. The Pearl study measured responses not just for correctness, but for completeness, prioritization, and professional judgment, criteria often absent from automated benchmarks.
The findings indicate that today’s top models may be converging on a performance plateau that is still well below the expert level. No model tested broke the 73% alignment barrier in aggregate, suggesting a potential ceiling for current AI architectures when faced with the ambiguity and complexity of professional work.
A High-Stakes Reality Check
Nowhere is this performance gap more alarming than in critical professional domains. The study revealed that AI performance varies sharply by subject, with some widely used models scoring as low as 20% in the legal and health sectors. In these fields, a 30%—or even 80%—error rate is not just a statistical anomaly; it represents a significant risk of harm, malpractice, or severe financial loss.
In healthcare, for example, professionals are exploring AI as an assistive tool for diagnostics and treatment planning. However, the prospect of an AI providing advice that misaligns with expert medical consensus 30% of the time is a non-starter for direct patient care. This reality has led regulatory bodies like the FDA to develop stringent guidelines for AI in medical devices, demanding robust, real-world clinical validation that goes far beyond standard benchmarks.
The legal profession faces a similar crisis of confidence. Recent incidents of AI models “hallucinating” non-existent legal precedents have made firms acutely aware of the risks. Relying on an AI for legal advice that is frequently misaligned with expert judgment could expose a lawyer to ethical violations and malpractice claims. As a result, bar associations are beginning to issue guidance that emphasizes the non-negotiable role of human oversight and verification.
This cautious sentiment is echoed in the financial sector, where regulators are increasing their scrutiny of AI-driven systems used for credit scoring, investment advice, and risk management. The potential for biased or simply incorrect AI outputs to cause market instability or discriminatory practices has put the industry on high alert.
Diminishing Returns and a New Standard for Trust
Adding another layer of complexity, the Pearl evaluation found that simply allocating more computational power for reasoning does not guarantee better judgment. So-called maximum-reasoning configurations only improved performance by a slim one to 2.6 percentage points over minimal-reasoning settings. In some instances, increased computation even led to lower-quality, over-complicated responses, suggesting that more processing power does not reliably equate to better professional insight.
In response to these challenges, Pearl’s methodology proposes a different path forward for AI evaluation. By using a private dataset of real-world professional questions and having responses scored by credentialed experts, the leaderboard aims to create a more grounded and practical standard for what constitutes “good” AI performance. This human-in-the-loop approach, while more resource-intensive than automated benchmarks, reflects a growing consensus that true AI trustworthiness can only be measured against the standards of the humans it is designed to serve.
While AI developers like OpenAI and Anthropic have publicly stated their commitment to safety and alignment, third-party evaluations like Pearl's provide an essential, independent perspective. They underscore a crucial turning point for the industry: the path to deploying AI in the most critical sectors of our economy will not be paved by acing synthetic tests, but by earning the trust of the human experts who work in them every day.