AI's New Blueprint: MLPerf v6.0 Spotlights MoE Models and Cloud Dominance
- 671 billion parameters in DeepSeek V3 benchmark, with only 37 billion activated per token, showcasing sparse computation efficiency.
- 95 unique systems submitted, utilizing 13 different hardware accelerators and 19 different host processors, highlighting ecosystem diversity.
- Cloud submissions doubled in six months, signaling a shift from on-premises to cloud-based AI training.
Experts would likely conclude that MLPerf v6.0 results underscore a pivotal shift toward sparse computation architectures, cloud dominance in AI training, and a thriving diversity of hardware and software solutions, fostering innovation and competition in the AI infrastructure landscape.
AI's New Blueprint: MLPerf v6.0 Spotlights MoE Models and Cloud Dominance
SAN FRANCISCO, CA – June 16, 2026 – The world of artificial intelligence infrastructure is undergoing a seismic shift, and the latest results from industry standard-bearer MLCommons provide the clearest map of the new terrain. The release of the MLPerf® Training v6.0 benchmark suite reveals a decisive industry-wide pivot towards sparse computation architectures, a dramatic surge in cloud-based AI training, and a flourishing diversity of hardware and software solutions competing for dominance.
This round introduces two pivotal new benchmarks, DeepSeek V3 and GPT-OSS 20B, both built on the increasingly popular Mixture-of-Experts (MoE) architecture. The results from a record 24 participating organizations underscore a dual trend: a convergence on new model architectures while the underlying systems to train them become more varied and accessible than ever before.
“It’s an exciting moment for the community,” said Shriya Rishab, MLPerf Training Working Group co-chair. “We’re seeing strong convergence on a set of best practices for training AI models, but at the same time there is increasing technical diversity in the underlying frameworks and systems that are being used to host and run them.”
The Era of Sparsity: How MoE is Redefining AI Efficiency
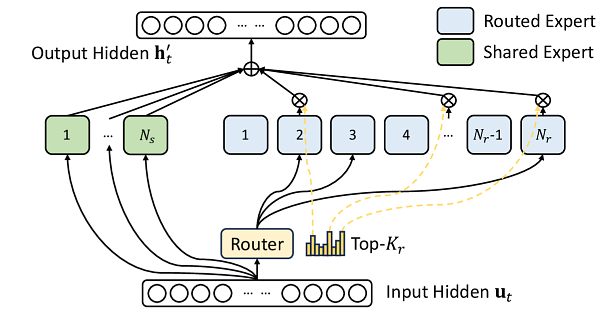
The most significant technical takeaway from the v6.0 results is the industry's full-throated embrace of sparse computation, exemplified by MoE models. Unlike traditional dense models where every parameter is engaged during computation, MoE architectures use a sophisticated 'router' to direct each piece of data to a small subset of specialized 'expert' networks. This allows for the creation of models with staggering parameter counts while keeping computational costs manageable, a critical factor for both performance and economic viability.
MLCommons has codified this trend with its two new benchmarks. The first, DeepSeek V3, is a heavyweight test designed to evaluate production-scale training systems. With 671 billion total parameters—of which only 37 billion are activated per token—it represents the cutting edge of large-scale, open-weight models. According to MLCommons, it also exercises critical innovations now standard in the industry, including Multi-head Latent Attention (MLA) for memory optimization and advanced load-balancing techniques.
“Sparse computation is a dominant trend in AI right now,” Rishab stated. “Over the past two years, all of the major new generative AI models have utilized a sparse computation architecture... We have introduced our new DeepSeek V3 benchmark to test large-scale sparse computation training systems, and in fact it is now the largest benchmark in our suite.”
On the other end of the spectrum is GPT-OSS 20B. With 21 billion total parameters and 3.6 billion activated per token, it provides a much more accessible entry point for organizations to benchmark MoE performance. Crucially, it is designed to run on hardware as small as a single 8-GPU node, democratizing the ability to evaluate the complex logic of sparse models without requiring a massive data center. This benchmark lowers the barrier to entry, allowing a wider range of players to innovate and build advanced capabilities.
Cloud's Ascent and the Democratization of AI Training
Perhaps the most impactful trend for institutional investors and CTOs is the dramatic acceleration of AI training's migration to the cloud. Submissions from cloud-based systems more than doubled compared to the last benchmark round just six months ago, signaling a fundamental shift in how organizations access and deploy high-performance computing.
This move from bespoke, on-premises supercomputers to a flexible, utility-based service model has profound implications. It lowers the formidable capital expenditure historically required for cutting-edge AI, allowing companies to rent capacity from specialized cloud providers instead. This flexibility is key for navigating the dynamic and often unpredictable cycles of AI development.
“There are more ways of getting your AI training than ever before,” noted Pavan Yalamanchili, MLPerf Working Group co-chair. “Several companies now offer training systems in the cloud, complementing the on-premises systems that continue to be built out at a furious pace.”
The performance results paint a vivid picture of a fiercely competitive cloud market. CoreWeave, a specialized AI cloud provider, posted the fastest time on the massive DeepSeek V3 benchmark using a cluster of 8,192 NVIDIA GB300 GPUs. Hyperscaler Microsoft Azure showcased its scale by training the Llama 3.1 405B model in just over seven minutes on 8,192 NVIDIA GB200 systems. Meanwhile, AMD and Oracle Cloud Infrastructure collaborated on a 512-GPU submission, demonstrating strong multi-node performance.
This intense competition among cloud providers not only spurs innovation but also creates a buyer's market, giving organizations more choice and leverage when crafting their AI infrastructure strategies.
A Diverse Ecosystem Validated by Performance
The v6.0 results also put to rest any notion of a monolithic AI ecosystem. With 95 unique systems submitted, utilizing 13 different hardware accelerators and 19 different host processors, the benchmarks reveal a 'Cambrian explosion' of AI hardware and software solutions. This diversity is a sign of a healthy, robust market where multiple technical pathways are being explored to optimize performance and efficiency.
A key area of this technical diversity is the implementation of low-precision data formats, particularly 4-bit floating point (FP4). Using FP4 dramatically reduces a model's memory footprint and can accelerate computation, but it introduces challenges in maintaining numerical stability and accuracy. Different hardware vendors have developed their own FP4 recipes, and MLPerf provides a crucial, neutral ground for evaluating their real-world effectiveness.
“The diversity of FP4 implementations we see in the submissions is not surprising,” said Yalamanchili. “But here is where MLPerf’s benchmarking delivers critical insight and value: it allows stakeholders to understand which implementations deliver the best performance for their specific needs. In particular, because MLPerf benchmarks require submissions to meet an accuracy threshold, we shine a spotlight on the differences in performance that these kinds of hardware and implementation design choices can lead to.”
This round saw NVIDIA's Blackwell platform, with its NVFP4 capabilities, deliver leading performance across all benchmarks. At the same time, AMD showcased significant generational improvements with its MI355X accelerators, demonstrating a competitive production-ready MXFP4 training recipe. This transparent, head-to-head comparison is invaluable for decision-makers evaluating long-term hardware investments.
MLCommons: The Standard-Bearer for a Competitive AI Future
Underpinning all these trends is the vital role of MLCommons as an open, collaborative consortium. The record participation from 24 organizations—including first-time submitters Inventec, Netweb Technologies India LTD, TTA, and Vultr—validates the benchmark's credibility and its central importance to the industry.
“We would especially like to welcome first-time MLPerf Training submitters,” said David Kanter, Head of MLPerf at MLCommons, highlighting the consortium's growing reach.
For institutional investors, analysts, and technology leaders, MLPerf acts as the unseen hand guiding the market toward transparency and fair competition. By providing standardized, peer-reviewed metrics, it cuts through marketing hype and allows for rigorous, data-driven evaluation of performance claims. This fosters a competitive environment that accelerates innovation across the entire ecosystem, from silicon to software to cloud services. These latest benchmarks not only chart the current state of AI training but also illuminate the collaborative and competitive path toward the next generation of intelligent systems.
📝 This article is still being updated
Are you a relevant expert who could contribute your opinion or insights to this article? We'd love to hear from you. We will give you full credit for your contribution.
Contribute Your Expertise →