- 37 hours of synchronized speech, motion, and facial expression data in the SuSuInterActs Dataset
- 676 hours of motion sequences used to pre-train the Motion Foundation Model
- 0.3 seconds to generate a six-second motion sequence in real-time
Experts would likely conclude that SentiAvatar represents a significant advancement in overcoming the uncanny valley through its open-source framework, comprehensive dataset, and real-time motion synchronization capabilities, positioning it as a strong contender in the digital human market.
SentiAvatar Aims to End the Uncanny Valley with Open-Source AI
JINAN, China – April 09, 2026 – Startup SentiPulse, in a significant collaboration with researchers from Renmin University of China, has released SentiAvatar, an open-source framework designed to create interactive 3D digital humans that move and express themselves with unprecedented naturalism. The release, now available on GitHub, aims to solve one of the most persistent challenges in artificial intelligence and computer graphics: the "uncanny valley," where near-human avatars provoke feelings of unease rather than connection.
The project provides developers with a complete toolkit, including the SentiAvatar framework, a character model named SUSU, and a vast dataset of human motion. By making these resources freely available, the creators hope to accelerate a new era of human-AI interaction, where digital companions, game characters, and virtual assistants can communicate with the emotional nuance of a real person.
The Soul of the Machine: Escaping the Uncanny Valley
For decades, developers and roboticists have struggled with the uncanny valley, a concept first described by Masahiro Mori in 1970. The theory posits that as an artificial entity becomes more human-like, our affinity for it increases, but only up to a point. When it becomes almost perfectly human but contains subtle flaws—stiff facial expressions, gestures that don't match vocal tone, or dead-looking eyes—our positive feelings abruptly plummet into revulsion.
This issue has plagued the development of digital humans. While graphics have become photorealistic, motion and expression have lagged. An avatar might speak, but its body language often feels disconnected from the meaning and emotion of its words. Human communication is deeply multimodal; a shrug, a raised eyebrow, or a subtle nod are not mere embellishments but integral parts of conveying intent, doubt, or agreement. The press release describes these nonverbal signals as "the soul of real conversation."
SentiAvatar confronts this challenge directly. The framework is engineered to synchronize speech, gesture, and facial expression in real-time, addressing three core roadblocks that have historically hindered progress: a lack of high-quality training data, difficulty in understanding the semantics of combined actions, and the challenge of aligning motion with the rhythm of live speech.
Under the Hood: A Three-Pronged Technical Approach
The SentiAvatar framework is built on a foundation of extensive data and a novel architecture. The team’s open-source release includes three key components designed to work in concert to generate lifelike behavior.
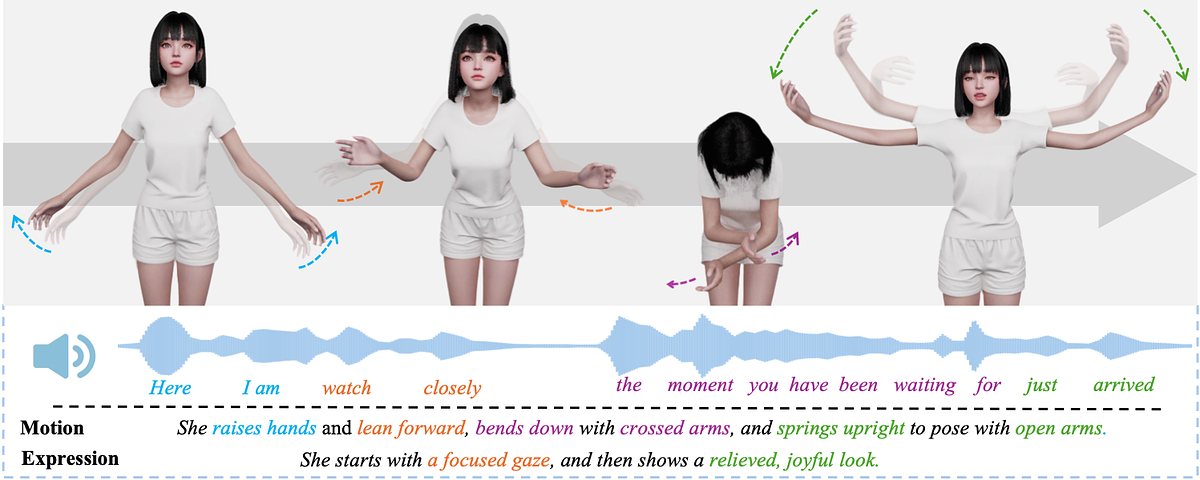
First is the SuSuInterActs Dataset, a massive collection of high-quality motion data. Built around a single character persona, SUSU, described as a warm and lively 22-year-old, the dataset contains 37 hours of synchronized speech, annotated text, full-body motion, and facial expressions across 21,000 clips. This resource helps address a significant bottleneck in the field, particularly the scarcity of comprehensive Chinese-language conversational data.
Second, the system is powered by a proprietary Motion Foundation Model. Recognizing that conversational data alone is too limited, the team pre-trained this model on a heterogeneous library of over 200,000 motion sequences, totaling approximately 676 hours. This process allows the AI to learn a general vocabulary of human movement that extends far beyond simple dialogue gestures, giving its actions a more robust and natural foundation.
The third and most innovative element is the core architecture, dubbed Plan-Then-Infill. This dual-channel system separates the planning of an action from its execution. One channel determines the semantic intent—what gesture or expression is appropriate for the words being spoken—while the other channel "infills" the precise, frame-by-frame motion needed to perform it naturally. This separation allows for more accurate and context-aware movements. The framework boasts state-of-the-art performance, capable of generating a six-second motion sequence in just 0.3 seconds and supporting continuous, "infinite-turn" streaming. This means an avatar can react and gesture mid-conversation without waiting for a speaker to finish a sentence, a critical factor in eliminating the awkward pauses that make many digital humans feel robotic.
A Crowded Field: Navigating the Digital Human Market
SentiPulse enters a competitive landscape populated by tech giants and specialized startups all vying to create the most believable digital beings. Companies like NVIDIA with its Omniverse Avatar Cloud Engine (ACE) and Epic Games with its popular MetaHuman Creator offer powerful toolkits for developers. Meanwhile, firms such as Soul Machines and UneeQ specialize in creating "emotionally intelligent" AI avatars for customer service and brand representation.
Against these established players, SentiAvatar’s primary distinction is its open-source strategy combined with its specific technical focus on real-time conversational coherence. While tools like MetaHuman excel at creating visually stunning static characters, and platforms like NVIDIA's ACE offer a suite of modular AI services, SentiAvatar provides an integrated, end-to-end framework specifically for generating semantically aware motion from live audio. The creators claim their approach yields superior results compared to other models, which they argue can suffer from disconnected rhythm, semantic misinterpretation, or unstable, distorted movements.
By providing not just the model but also the extensive SuSuInterActs dataset, the project gives the global developer community a powerful sandbox for experimentation that might otherwise be locked behind proprietary walls.
The Open-Source Gambit and China's AI Prowess
The decision to open-source such a sophisticated technology is a calculated strategic move. For a young company like SentiPulse, founded only in September 2025, this gambit could rapidly build a global community, accelerate innovation beyond its internal capacity, and establish its framework as a foundational standard in the emerging "digital life" ecosystem. This strategy aims to attract top-tier talent and foster collaboration across industries, from gaming and film to robotics and virtual reality. While open-sourcing AI carries inherent risks, such as potential misuse, the move signals a belief that the benefits of community-driven development outweigh the drawbacks.
This release also highlights the growing strength and sophistication of China's AI sector. The collaboration between SentiPulse and the Gaoling School of Artificial Intelligence (GSAI) at Renmin University of China is a prime example of the powerful synergy between the country's burgeoning tech industry and its top-tier academic institutions. Renmin University is highly ranked globally for its AI and computer science programs, and GSAI's faculty includes leading researchers with experience at major international tech labs.
By tackling a complex problem like the uncanny valley and contributing the solution to the global community, the SentiAvatar project serves as a statement of technical leadership. The team has extended an open invitation to researchers and developers worldwide to build upon their work, pushing the boundaries of what is possible in the quest to create digital life that is not just intelligent, but also expressive and deeply human.