Beyond the Hype: MLPerf v6.0 Shows What's Really Driving AI Forward
- 671 billion parameters: DeepSeek V3 is the largest benchmark in MLPerf v6.0, testing production-scale AI systems.
- 8,192 GPUs: CoreWeave achieved a record 2.02-minute training time on DeepSeek V3 using this setup.
- 95 unique systems: MLPerf v6.0 saw submissions from 24 organizations using 13 different hardware accelerators.
Experts would likely conclude that MLPerf v6.0 confirms the industry's shift toward sparse models and cloud-based AI training, marking a significant evolution in AI architecture and accessibility.
Beyond the Hype: MLPerf v6.0 Shows What's Really Driving AI Forward
SAN FRANCISCO, CA – June 16, 2026 – In the relentless, often deafening, hype cycle of artificial intelligence, it can be difficult to distinguish genuine progress from marketing gloss. But today, the industry’s de facto scorekeeper, MLCommons®, has provided a clear signal through the noise. The release of the MLPerf® Training v6.0 benchmark results offers a grounded, data-backed look at the real forces shaping the future of AI, confirming two seismic shifts: the architectural pivot to hyper-efficient “sparse” models and the undeniable migration of high-performance AI training to the cloud.
These benchmarks are more than just a leaderboard; they are a peer-reviewed X-ray of the entire AI ecosystem. “It’s an exciting moment for the community,” said Shriya Rishab, MLPerf Training Working Group co-chair. The results, she noted, show “strong convergence on a set of best practices for training AI models, but at the same time there is increasing technical diversity in the underlying frameworks and systems.” For anyone trying to understand the why behind the buy in the AI space, these results are essential reading.
The New Architecture of Intelligence: Sparsity Takes Center Stage
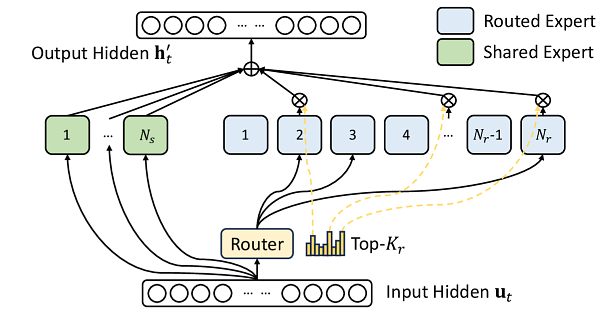
The most significant takeaway from v6.0 is the formal acknowledgment of a new dominant design pattern in AI: sparse computation, specifically through Mixture-of-Experts (MoE) architectures. For the past two years, this has been the secret sauce behind many of the largest and most capable generative AI models. Now, MLPerf has codified it into the benchmark standard.
MoE is a clever solution to an existential problem for AI developers: how do you build models with trillions of parameters without requiring the energy budget of a small country to train and run them? The MoE approach uses a “smart router” that directs each piece of data (or token) to a small subset of specialized sub-networks, or “experts.” This means a model can possess a vast repository of knowledge (total parameters) while only activating a small fraction of it for any single task, dramatically reducing the computational cost.
MLPerf v6.0 introduces two benchmarks to measure this new paradigm. The first, DeepSeek V3, is a behemoth designed to test systems at production scale. With 671 billion total parameters, it is now the largest benchmark in the suite, pushing the limits of training systems with advanced features like Multi-head Latent Attention (MLA) for memory optimization. On the other end, GPT-OSS 20B provides a crucial entry point. With a more modest 21 billion parameters, it allows organizations to test the complex logic of MoE architectures on hardware as small as a single 8-GPU server. As Rishab explained, this benchmark was carefully designed to reduce the cost of participation, even allowing training from randomized weights to avoid massive checkpoint downloads.
This isn't just a technical curiosity; it's a fundamental shift in commercial strategy. The performance of systems on these benchmarks—like CoreWeave’s record-setting 2.02-minute training time on DeepSeek V3 using 8,192 NVIDIA GPUs, or NVIDIA’s own Blackwell platform setting records on both new MoE workloads—demonstrates that the industry is rapidly coalescing around this efficient architecture. It validates the massive R&D investment in MoE and provides the first standardized yardstick for comparing the performance of these complex systems.
From On-Prem to Cloud: The Democratization of AI Power
If the first story is about a change in architecture, the second is about a change in address. The v6.0 results reveal a dramatic acceleration of AI training's move to the cloud, with the number of cloud-based system submissions more than doubling in just six months. This trend signifies the maturation of the AI market, moving from a domain of bespoke, on-premises supercomputers to a more accessible, utility-based service model.
This shift is democratizing access to high-performance computing. Companies no longer need to invest tens of millions in capital expenditures to build their own AI data centers. Instead, they can rent that capacity from specialized providers. “There are more ways of getting your AI training than ever before,” noted Pavan Yalamanchili, MLPerf Working Group co-chair.
The results from cloud providers like CoreWeave, Azure, and Oracle are telling. They are not submitting results on theoretical, lab-only setups. Instead, they are demonstrating record-breaking performance on the same production-ready infrastructure that is available to their customers. This proves that world-class AI training capability is no longer the exclusive purview of hyperscale tech giants; it is a commodity that can be purchased on demand. This lowers the barrier to entry for thousands of startups and enterprises, allowing them to focus on building innovative AI applications rather than managing complex infrastructure.
A Cambrian Explosion in AI Hardware and Software
Beneath the headline trends, the MLPerf results reveal a vibrant and diversifying hardware and software ecosystem. The v6.0 round saw a record 95 unique systems submitted from 24 different organizations, utilizing 13 different hardware accelerators and 19 different host processors. While NVIDIA’s new Blackwell platform demonstrated formidable performance across the board, the strong showing from a variety of on-premises and cloud providers using diverse hardware configurations points to a healthy, competitive market.
This diversity is critical for the long-term health of the AI industry, preventing vendor lock-in and fostering innovation. One area of intense exploration is the use of lower-precision data formats, like the FP4 recipes mentioned in the results. In simple terms, these formats allow hardware to process more data faster and more efficiently. However, different implementations can have vastly different impacts on model accuracy.
This is where the benchmark’s true value shines. As Yalamanchili pointed out, because MLPerf requires all submissions to meet a strict accuracy threshold, it “shine[s] a spotlight on the differences in performance that these kinds of hardware and implementation design choices can lead to.” It allows stakeholders to cut through marketing claims and understand which solutions deliver not just speed, but accurate, usable results for their specific needs. This rigorous, peer-reviewed process is what transforms a collection of speed tests into a powerful engine for industry-wide innovation, ensuring that the race for performance is always tethered to the pursuit of real-world value.
📝 This article is still being updated
Are you a relevant expert who could contribute your opinion or insights to this article? We'd love to hear from you. We will give you full credit for your contribution.
Contribute Your Expertise →